Filed under: Digital workplace, Intranets, Search tools
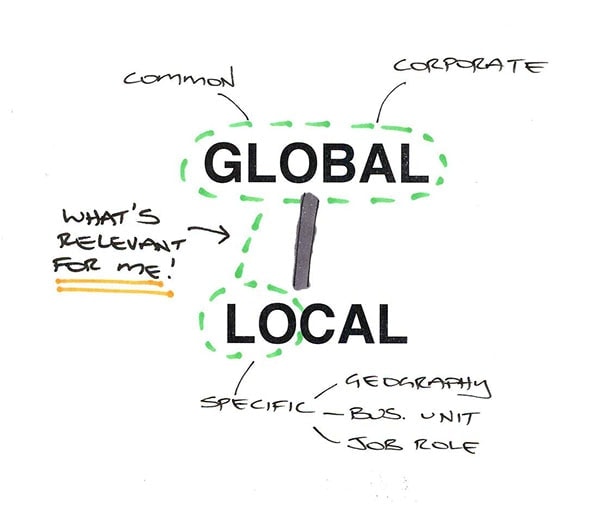
This is a sketch that I drew while sitting in one of the enterprise search presentations at the recent KMWorld conference in Washington, DC. It explores the question: what should enterprise search be searching?
The starting point is the global/local model for intranets, that we’ve described earlier. This distinguishes between two types of information:
- Global information, that is common across the whole organisation, and used by all staff.
- Local information, which is specific to a particular group of staff, according to geography, business unit and/or job role.
With this model as a foundation, it then becomes easy to outline the default scope of enterprise search:
By default, enterprise search should return results from all global information, plus the portion of local content that is relevant to me.
Easy to say, but much harder to do! Like all simple models, it’s deceptive how much thinking and work is required to deliver it in the real world.
This is not just a matter of installing a fancy search engine, and hoping that it’s smart enough to work all this out for itself. Instead, the these building blocks must be in place:
- There must be a clear framework for the overall intranet/collaboration landscape, that defines the purpose and audience for the many different spaces.
- The identity of staff must be known, along with an understanding of what information is relevant to them.
- Enterprise search must tailor results by default, based on searching just that portion of local space that is relevant to the current users.
This perhaps turns things on its head. Instead of hoping that enterprise search will make sense of a chaotic landscape, it suggests that delivering an effective search relies on bringing structure to information first.
What are your thoughts on this?



